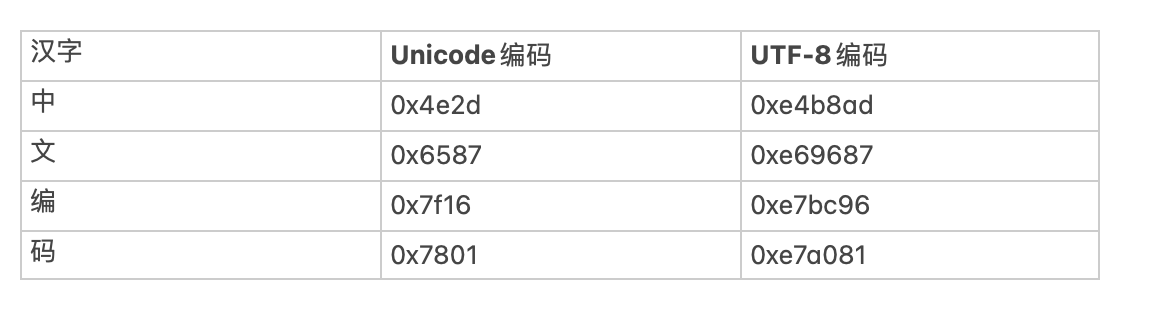
世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。
ASCII
ASCII码就是一种编码,字母A的编码是十六进制的0x41,字母B是0x42,ASCII编码最多只能有127个字符
UTF - 8
有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode,就像它的名字都表示的,这是一种所有符号的编码。
Unicode 是互联网统一的符号集,只规定了符号唯一的二进制代码值,却没有规定这个二进制代码应该如何存储。UTF-8是一种针对Unicode的可变长度字符编码,UTF-8用1到4个字节编码Unicode字符,在互联网上使用最广的一种 Unicode 的实现方式。
UTF-8 是 Unicode 的实现方式之一
Base64编码
Base64编码是对二进制数据进行编码,表示成文本格式,这样在很多文本协议(电子邮件协议)中就可以处理二进制数据
Base64编码可以把任意长度的二进制数据变为纯文本,且只包含AZ、az、0~9、+、/、=这些字符
原理是把3字节的二进制数据按6bit一组,用4个int整数表示,然后查表,把int整数用索引对应到字符,得到编码后的字符串。
举个例子:
3个byte数据分别是e4、b8、ad,按6bit分组得到39、0b、22和2d:
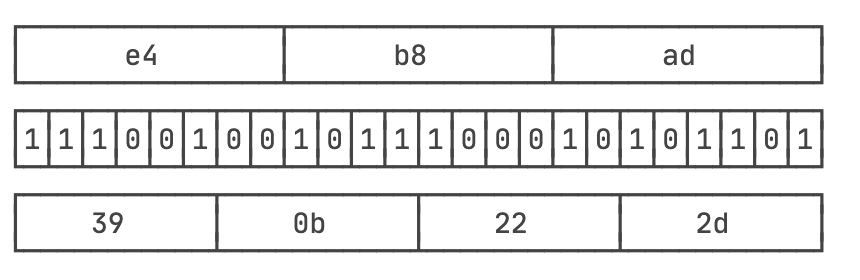
因为6位整数的范围总是063,所以,能用64个字符表示:Z对应索引0
字符A25,z对应索引26
字符a51,9对应索引52~61,
字符0
最后两个索引62、63分别用字符+和/表示
因为标准的Base64编码会出现+、/和=,所以不适合把Base64编码后的字符串放到URL中。一种针对URL的Base64编码可以在URL中使用的Base64编码,它仅仅是把+变成-,/变成_
Base64编码的缺点是传输效率会降低,因为它把原始数据的长度增加了1/3