从开发角度来看,总体来说分以下几个过程
- URL解析
- DNS解析:将域名解析成IP地址
- TCP连接:三次握手
- 发送HTTP请求
- 服务器处理请求并返回HTTP报文
- 浏览器解析渲染页面
- TCP断开连接:四次挥手
开始
URL解析
分析所需要使用的传输协议和请求资源的路径,如果输入的URL中的协议或者主机名不合法,
将会把地址栏中输入的内容传递给搜索引擎,如果没有问题,浏览器会检查URL中是否出现了非法字符,如果存在非法字符,则对非法字符进行转义后再进行下一过程。
缓存检查
浏览器会判断所请求的资源是否在缓存里,如果请求的资源在缓存里并且没有失败,那么就直接使用,否则向服务器发起新的请求。
DNS解析
首先会判断本地是否有该域名的IP地址的缓存,如果没有则向本地DNS服务器发起请求,本地DNS服务器也会先检查是否存在缓存,如果没有就会先向根域名服务器发起请求,获得负责的顶级域名服务器的地址后,再向顶级域名服务器请求,然后获得负责的权威域名服务器的地址后,再向权威域名服务器发起请求,最终获得域名的 IP 地址后,本地 DNS 服务器再将这个 IP 地址返回给请求的用户。
1 | 用户向本地DNS服务器发起请求属于递归请求 |
套接字生成
当浏览器得到IP地址后,数据传输还需要知道目的主机的MAC地址,因为应用层发送数据给传输层,TCP协议会指定元端口号和目的端口号,然后下发给网络层,网络层会将本机地址作为源地址,获取的IP地址作为目的地址,然后下发给数据链路层,数据链路层的发送需要加入通信双方的MAC地址,我们本机的MAC地址作为源MAC地址,目的MAC地址需要按分情况处理。通过将IP地址与我们本机的子网掩码相与,我们可以判断我们是否与请求主机在同一个子网里,如果在同一个子网里,可以使用ARP协议获取到目的主机的MAC地址,如果不在一个子网里,那么我们的请求应该转发给我们的网关,由它代为转发,此时通过ARP协议来获取网关的MAC地址。此时目的主机的MAC地址应该为该网关的地址。
三次握手
…
HTTPS协议的话,还会有TLS的一个四次握手的过程
…
服务器处理请求并返回HTTP报文
当页面请求发送到服务端后,服务端会返回一个html文件作为响应,浏览器接收到响应后,开始对html文件进行解析,开始页面的渲染过程。
浏览器解析渲染页面
浏览器首先会根据 html 文件构建 DOM 树,根据解析到的 css 文件构建 CSSOM 树,如果遇到 script 标签,则判端
是否含有 defer 或者 async 属性,要不然 script 的加载和执行会造成页面的渲染的阻塞。当 DOM 树和 CSSOM 树建
立好后,根据它们来构建渲染树。渲染树构建好后,会根据渲染树来进行布局。布局完成后,最后使用浏览器的 UI 接口对页
面进行绘制。这个时候整个页面就显示出来了。
四次挥手
…
Tips
CDN
CDN是一个内容分发网络,通过对源网站资源的缓存,利用本身多台位于不同地域,不同运营商的服务器,向用户提供资源就近访问的功能,也就是说用户的请求并不是直接发送给源网站,而是发送给CDN服务器,由CDN服务器将请求定位到最近的含有该资源的服务器上去请求,这样有利于提高网站的访问速度,同时通过这种方式也减轻了源服务器的访问压力。
正向代理和反向代理
常说的代理就是指正向代理,正向代理的过程隐藏了真实的请求客户端,服务端不知道真实的客户端是谁,客户端请求的服务都被代理服务器代替来请求。
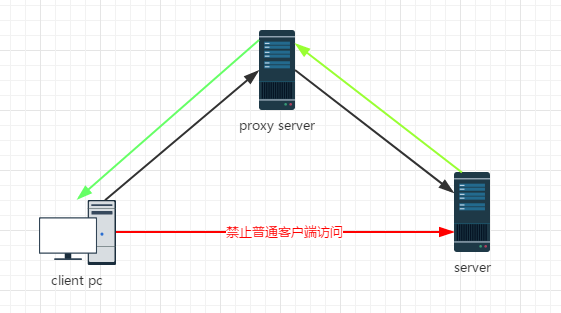
反向代理隐藏了真实的服务端,当我们请求一个网站的时候,背后可能有成千上万台服务器为我们服务,但具体是哪一台,也不需要知道,我们只需要知道反向代理是谁就好了,反向代理服务器会帮我们把请求转发到真实的服务器那里去。 反向代理一般用来实现负载均衡。
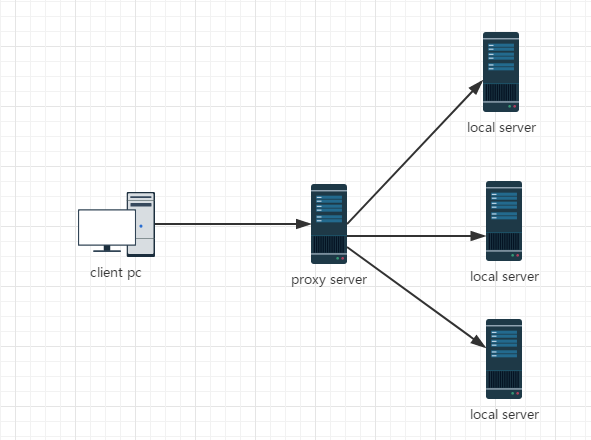
负载均衡的两种实现方式
- 反向代理
用户的请求都发送到反向代理服务上,然后由反向代理服务器来转发请求到真实的服务器上,以此来实现集群的负载均衡。 - DNS方式
DNS可以用于在冗余的服务器上实现负载均衡,因为现在一般的大型网站使用多台服务器提供服务,因此一个域名可能会对应多个服务器地址,当用户向网站域名请求的时候,DNS 服务器返回这个域名所对应的服务器 IP 地址的集合,但在
每个回答中,会循环这些 IP 地址的顺序,用户一般会选择排在前面的地址发送请求。以此将用户的请求均衡的分配到各个不同的服务器上,这样来实现负载均衡。这种方式有一个缺点就是,由于 DNS 服务器中存在缓存,所以有可能一个服务器出现故障后,域名解析仍然返回的是那个 IP 地址,就会造成访问的问题。
URL
URL(Uniform Resource Locator),统一资源定位符,用于定位互联网上资源,俗称网址。
scheme: // host.domain:port / path / filename ? abc = 123 # 456789
1 | scheme - 定义因特网服务的类型。常见的协议有 http、https、ftp、file, |
即时通讯的实现,短轮询、长轮询、SSE 和 WebSocket 间的区别
短轮询和长轮询的目的都是用于实现客户端和服务器端的一个即时通讯。
短轮询
短轮询的基本思路就是浏览器每隔一段时间向服务器发送 http 请求,服务器端在收到请求后,不论是否有数据更新,都直接进行响应。这种方式实现的即时通信,本质上还是浏览器发送请求,服务器接受请求的一个过程,通过让客户端不断的进行请求,使得客户端能够模拟实时地收到服务器端的数据的变化。这种方式的优点是比较简单,易于理解。缺点是这种方式由于需要不断的建立 http 连接,严重浪费了服务器端和客户端的资源。当用户增加时,服务器端的压力就会变大,这是很不合理的。
长轮询
长轮询的基本思路是,首先由客户端向服务器发起请求,当服务器收到客户端发来的请求后,服务器端不会直接进行响应,而是先将这个请求挂起,然后判断服务器端数据是否有更新。如果有更新,则进行响应,如果一直没有数据,则到达一定的时间限制才返回。
客户端 JavaScript 响应处理函数会在处理完服务器返回的信息后,再次发出请求,重新建立连接。长轮询和短轮询比起来,它的优点是明显减少了很多不必要的 http 请求次数,相比之下节约了资源。长轮询的缺点在于,连接挂起也会导致资源的浪费。
SSE
SSE 的基本思想是,服务器使用流信息向服务器推送信息。严格地说,http 协议无法做到服务器主动推送信息。但是,有一种变通方法,就是服务器向客户端声明,接下来要发送的是流信息。也就是说,发送的不是一次性的数据包,而是一个数据流,会连续不断地发送过来。这时,客户端不会关闭连接,会一直等着服务器发过来的新的数据流,视频播放就是这样的例子。SSE 就是利用这种机制,使用流信息向浏览器推送信息。它基于 http 协议,目前除了 IE/Edge,其他浏览器都支持。它相对于前面两种方式来说,不需要建立过多的 http 请求,相比之下节约了资源。
WebSocket
WebSocket 是 Html5 定义的一个新协议,与传统的 http 协议不同,该协议允许由服务器主动的向客户端推送信息。使用 WebSocket 协议的缺点是在服务器端的配置比较复杂。WebSocket 是一个全双工的协议,也就是通信双方是平等的,可以相互发送消息,而 SSE 的方式是单向通信的,只能由服务器端向客户端推送信息,如果客户端需要发送信息就是属于下一个 http 请求了。